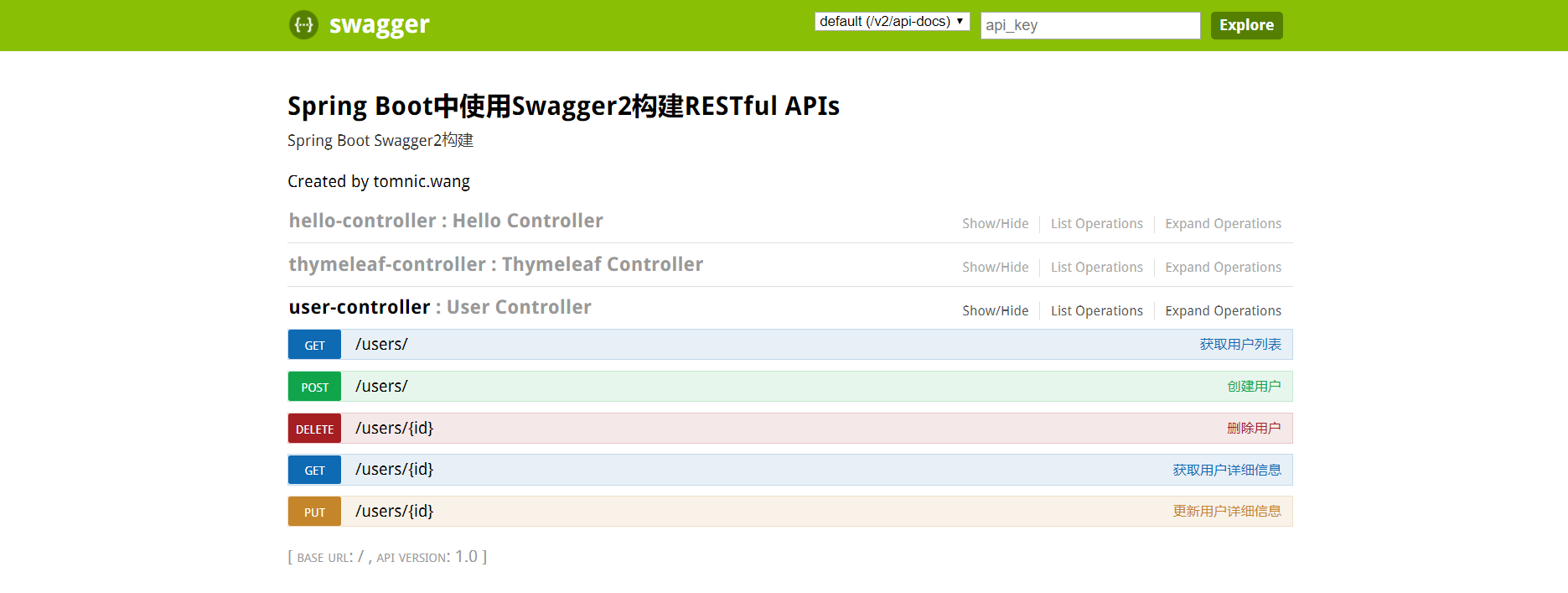
为什么字段尽可能用NOT NULL,而不是NULL
NULL为什么多人用?
1、NULL是创建数据表时默认的,初级或不知情的或怕麻烦的程序员不会注意这点。
2、很多人员都以为not null 需要更多空间,其实这不是重点。
3、重点是很多程序员觉得NULL在开发不用去判断插入数据,写sql语句的时候更方便快捷。
网上很多资料都有写:
Mysql官网文档:
“NULL columns require additional space in the rowto record whether their values are NULL. For MyISAM tables, each NULL columntakes one bit extra, rounded up to the nearest byte.”
-———————————————-
Mysql难以优化引用可空列查询,它会使索引、索引统计和值更加复杂。可空列需要更多的存储空间,还需要mysql内部进行特殊处理。可空列被索引后,每条记录都需要一个额外的字节,还能导致MYisam 中固定大小的索引变成可变大小的索引
——–这也是《高性能mysql第二版》介绍的
解读:
“可空列需要更多的存储空间”:需要一个额外字节作为判断是否为NULL的标志位
“需要mysql内部进行特殊处理”: 这是mysql索引统计,里面有介绍mysql怎么处理NULL。
注意:但把NULL列改为NOT NULL带来的性能提示很小,除非确定它带来了问题,否则不要把它当成优先的优化措施,最重要的是使用的列的类型的适当性